https://jangpiano-science.tistory.com/114?category=914257
미분 함수(중앙차분)를 이용한 경사하강법 파이썬 구현 및 시각화 / gradient descent using differentiation
<미분 함수를 이용한 경사하강법 파이썬 구현 및 시각화> 경사하강법(gradient descent)이란, 함수에서 기울어진 곳으로 이동해 함수의 극소값을 찾는 최적화(optimization) 알고리즘입니다. 최적화란,
jangpiano-science.tistory.com
앞 포스팅에서, 수치미분을 사용하여 신경망의 가중치 매개변수의 기울기를 구하는 방법을 소개하였습니다.
우리는 다음과 같은 순서로, 손실함수의 극소값을 찾았습니다.
1. 손실함수에 대한 가중치 매개변수의 기울기를 구한다.
2. 매개변수를 극솟값 쪽으로 이동하도록 업데이트 한다
3. 손실함수에 대한 가중치 매개변수의 기울기가 0에 근접할때까지, 1, 2번을 반복한다
신경망이 입력층(100개의 노드), 하나의 은닉층(300개의 노드), 출력층(10개의 노드) 총 세개의 층으로 이루어져 있다고 가정하였을때,
100*300*10 번의 수치미분 연산횟수가 필요합니다. 컴퓨터를 통한 계산이 이루어진다 하더라도, 굉장히 많은 시간이 소요되겠죠. 실제로, 많은 데이터를 다루는 딥러닝의 경우, 수치미분을 사용한 경사하강법을 구현 할때 많은 시간이 소요됩니다. 따라서, 수치미분으로 딥러닝을 구현하는것은 실용적이지 않습니다.
하나의 가중치 매개변수 값에 대한 손실함수의 미분값을 구할때, 앞선 매개변수에 대한 기울기가 구해져야만, 최종적으로 그 하나의 가중치 매개변수를 구할 수 있게 됩니다. 예를들어, 밑의 이미지를 참고해서 설명하자면, 분홍색으로 표기한 가중치 매개변수의 기울기를 구하고자 한다면, 노란색으로 칠한 두 가중치 매개변수의 기울기를 구하는 과정이 선행되어야만 합니다.
가장 간단한 신경망의 구현인 밑의 이미지에서도, 모든 가중치 매개변수에 대한 기울기를 구하기 위해 12번의 수치미분 과정이 필요하죠.
어마어마한 데이터로 신경망을 훈련시켜야 하는 딥러닝의 경우, 수치미분 사용한 최적화 매개변수를 구한다면, 정말 어마어마한 시간이 걸릴것입니다. (실제로 손글씨 데이터 - MNIST 의 훈련데이터를 가지고 최적화 매개변수를 찾을때, 미니배치로 구현하였음에도 불구하고 정말 많은 시간이 걸리더라구요. )

하지만, 그렇다고 해서 이 과정을 생략할수는 없습니다. 각각의 매개변수가 손실함수에 미치는 영향을 담은 정보가 사라진다면, 신경망 학습은 불가능하죠. 딥러닝 구현에 비효율적인 수치 미분을 대신하여, 가중치 매개변수의 기울기를 효율적으로 계산하는 '오차 역전파법 (Backpropagation)'을 소개해 보도록 하겠습니다.
역전파법을 설명하기에 앞서, 우선 역전파법을 구현하기 위한 핵심 개념인 '연쇄법칙(Chain Rule)'을 소개하겠습니다.
<연쇄법칙과 역전파>
연쇄법칙(Chain Rule)이란, " 합성함수의 미분은 합성함수를 구성하는 각 함수의 미분의 곱으로 나타내어진다." 는 정의입니다.
이는, 미분의 기초원리이기 때문에 연쇄법칙을 직접 수식으로 보면, 더 쉽게 이해하실 수 있으실거에요.

Z는 제곱함수( t^2 ) 와 덧셈함수 (x+y) 이 두개의 함수로 이루어져 있죠. 따라서 Z는 합성함수 입니다.
그렇다면, 직관적으로 x에 대한 Z의 미분값은 어떻게 구해질까요, 2(x+y)가 되겠죠. y에 대한 Z의 미분값 역시 2(x+y)가 됩니다.
x와 y에 대한 t의 미분값이 모두 1이기 때문에, x와 y에 대한 Z의 미분값이 2(x+y)*1 이 되는것입니다.
수식으로 나타내면 아래의 규칙성을 확인하실 수 있습니다.

말그대로 계산 과정을 나타낸 그래프인, 계산그래프(computational graph)를 이용하여 연쇄법칙을 표현해 봅시다.
계산그래프에서, 왼쪽에서 오른쪽 화살표로 계산이 진행되는 과정을 '순전파(forward propagation)'이라고 하고, 오른쪽에서 왼쪽 화살표로 계산이 진행되는 과정을 '역전파(back propagation)' 이라고 합니다.
순전파는, 계산이 진행되어 output을 내기까지의 과정을 말하고,
역전파는 각각의 과정이 output을 도출해내기까지 어떠한 직접적인 영향을 끼치는지 확인하기 위한 과정입니다.

이해를 돕기 위해 위의 연쇄법칙 계산그래프를 자세히 설명해보도록 하겠습니다.
- 순전파 과정 (왼쪽에서 오른쪽)
1. x와 y라는 +라는 노드에서 만난다. --> x+y
2. 1에서의 값이 t가 된다. --> t
3. t가 **2 노드를 만나 제곱된다. --> t^2
4. 그것이 최종 결과값이 된다. --> z
이 순전파 과정은 결과적으로 z = (x+y)^2를 도출해내기 위한 과정입니다.
이렇게 쉽고 직관적으로 표기와 이해가 가능한 수식을 뭐 이리 복잡하게 그래프로 표기해야 하나 싶으실거같기도 한데요.
계산그래프의 매력은 역전파 과정에서 드러납니다.
역전파 과정을 통해 각각의 변수가 최종 도출값인 Z에 어떠한 영향을 미치는지 확인해 보시죠.
-역전파 과정 (오른쪽에서 왼쪽)
1. z에 대한 결과값의 미분값 (z에 대한 z의 미분값)
2. t에 대한 결과값의 미분값
3. x에 대한 결과값의 미분값, y에 대한 결과값의 미분값
2번은, t의 변화가 Z를 얼마만큼 변화시키는지 알아보기 위한 과정이고,
3번은, x의 변화가 Z를 얼마만큼 변화시키는지 알아보기 위한 과정,
4번은, y의 변화가 Z를 얼마만큼 변화시키는지 알아보기 위한 과정이라고 할 수 있습니다.
역전파는 각각의 매개변수에 대한 미분값을 효율적으로 구할 수 있도록 도와줍니다. 계산그래프를 통해 역전파 과정에서의 수식을 한번 구현시켜 놓으면, 각각의 변수에 대한 손실함수의 미분값을 바로바로 구할 수있게 되는것이죠.
예를들면, z = t^2, t = (x+y) --> z = (x+y)^2에 대하여,
z에 대한 t의 미분식 구현 --> 2t
z에 대한 x의 미분식을 구현 --> 2t*1 --> 2(x+y)*1
z에 대한 y의 미분식 구현 --> 2t*1 --> 2(x+y)*1
귀찮더라도 계산그래프와 연쇄법칙을 이용해, 역전파 과정에서 이렇게 한번 식으로 구현해 놓으면, 각각의 변수가 최종 output에 얼마나 큰 영향을 미치는지 바로바로 파악하고, 그에 대응하여 변수를 변화시킬 수 있습니다.
수치적 미분과 비교하여 봤을때, 하나의 매개변수에 대한 미분값은, 에지(계산그래프에서의 노드와 노드를 연결하는 선)로 연결된 모든 매개변수에 대한 미분값 전부 계산한 후에만 도출 해 낼 수 있었습니다. 하지만, 오차역 전파법은 계산그래프를 이용해, 함수에 대한 국소적 미분을 모두 구해놓았기 때문에, 어떠한 매개변수에 대한 미분값이 궁금할때, 다른 매개변수값을 신경쓰지 않고 바로 구할 수 있습니다.
즉, x를 1만큼 바꾸면, Z는 얼마나 바뀔까를, 바로바로 구할 수 있게 되는것이죠.
즉, 신경망을 학습시킬때, 최종 목적은 '손실함수를 최소화하는 매개변수값 찾기'이죠. 오차역 전파법을 사용했을때, '매개변수 x를 1만큼 변화하면 손실함수의 값이 얼마나 바뀔까' 하는 x에 대한 손실함수의 기울기 값을 바로바로 구할 수 있게 됩니다.
<주요 함수에 대한 역전파 예시>
1. 덧셈
덧셈노드의 역전파를 생각해봅시다.
덧셈노드는 x와 y 변수로 Z라는 output을 내죠.
x+y = z
오른쪽에서 z에 대한 손실함수(L)의 기울기를 받을때, 이에 각각 x와 y에 대한 z의 기울기를 곱한다면,
연쇄법칙에 의해 x와 y에 대한 손실함수의 기울기를 구할 수 있겠죠?
그렇다면 x와 y변수의 변화가 전체 신경망의 output인 손실함수에 얼마나 큰 영향을 미치는지 알 수 있습니다.
z에서의 x변수의 계수가 1이기 때문에, z = x+y 를 x로 미분하면, 1이 됩니다. 따라서 z에 대한 손실함수(L)의 기울기에 1을 곱하면, x에 대한 손실함수의 기울기가 구해집니다. 즉, 덧셈노드의 역전파에서는 입력신호(z에 대한 L의 기울기)를 다음노드로 그대로 전달합니다.

<파이썬 구현>
*코드에서는 순전파의 출력값을 out으로 표현, 역전파에서의 입력값을 dout으로 표현하였습니다.
z = (x+y)를 구성하는 덧셈노드를 예를들때,
즉, 덧셈노드에 있어서, out = z 가 되겠교, dout = z에 대한 손실함수(L)의 기울기가 되겠죠.

2. 곱셈
곱셈노드의 역전파를 생각해봅시다.
곱셈노드는 x와 y 변수로 Z라는 output을 내죠.
x*y = z
오른쪽에서 z에 대한 손실함수(L)의 기울기를 받을때, 이에 각각 x와 y에 대한 z의 기울기를 곱한다면,
연쇄법칙에 의해 x와 y에 대한 손실함수의 기울기를 구할 수 있겠죠?
그렇다면 x와 y변수의 변화가 전체 신경망의 output인 손실함수에 얼마나 큰 영향을 미치는지 알 수 있습니다.
z = x*y 를 x로 미분하면, y가 됩니다. 따라서 z에 대한 손실함수(L)의 기울기에 y를 곱하면, x에 대한 손실함수의 기울기가 구해집니다. 즉, 곱셈노드의 역전파에서는 역전파의 입력신호(z에 대한 L의 기울기)에 순전파때의 입력신호값을 서로 바꾼 값을 곱해서 하류로 보냅니다.
즉,
x에 대한 손실함수(L)의 기울기 = z에 대한 손실함수의 기울기 * y
y에 대한 손실함수(L)의 기울기 = z에 대한 손실함수의 기울기 * x

<파이썬 구현>

3. 역수화
역수화 노드의 역전파를 생각해봅시다.
역수화 노드는 x라는 변수로 Z라는 output을 내죠.
1/x = Z
오른쪽에서 z에 대한 손실함수(L)의 기울기를 받을때, 이에 x에 대한 z의 기울기를 곱한다면,
연쇄법칙에 의해 x에 대한 손실함수의 기울기를 구할 수 있겠죠?
그렇다면 x변수의 변화가 전체 신경망의 output인 손실함수에 얼마나 큰 영향을 미치는지 알 수 있습니다.
z = 1/x 를 x로 미분하면, -x^-2가 됩니다. 따라서 z에 대한 손실함수(L)의 기울기에 -x^-2를 곱하면, x에 대한 손실함수의 기울기가 구해집니다.


4. 지수화
지수화 노드의 역전파를 생각해봅시다.
역수화 노드는 x라는 변수로 Z라는 output을 내죠.
e^x = z
오른쪽에서 z에 대한 손실함수(L)의 기울기를 받을때, 이에 x에 대한 z의 기울기를 곱한다면,
연쇄법칙에 의해 x에 대한 손실함수의 기울기를 구할 수 있겠죠?
그렇다면 x변수의 변화가 전체 신경망의 output인 손실함수에 얼마나 큰 영향을 미치는지 알 수 있습니다.
z = e^x 를 x로 미분하면, 그대로 e^x가 유지됩니다. 따라서 z에 대한 손실함수(L)의 기울기에 e^x를 곱하면, x에 대한 손실함수의 기울기가 구해집니다.
*순전파에서의 입력값이 -x인 경우, 역전파에서 e^-x를 곱해줍니다. 즉, 지수화 노드는 e^(순전파에서의 입력값)이 됩니다.

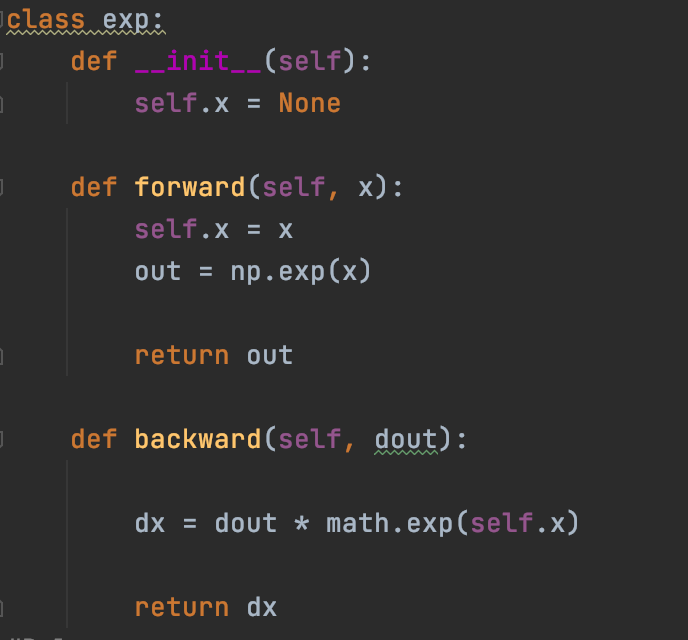
5. 시그모이드(Sigmoid) 활성화 함수
활성화 함수의 하나인, 시그모이드 함수를 먼저 살펴보시죠.
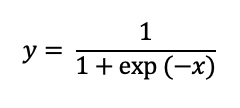
시그모이드 함수 노드의 순전파 먼저 생각해봅시다.
1. x인수를 받는다.
2. 1에서 받응 인수에 -를 붙인다.
3. 2에서 받은 인수를 지수화 한다.
4. 3에서 받은 인수에 1을 더한다
4. 4에서 받은 인수를 역수화한다.
시그모이드 함수 노드의 역전파를 생각해보시죠.
1. y에 대한 손실함수(L)의 기울기(dout)를 받는다.
2. 역수화 노드이기 때문에, 1에서 받은 인수에 -x^-2를 곱한다. (이는 -y^2 로 변수 변환하여 표현 가능)
3. 덧셈 노드이기 때문에, 2에서 받은 인수를 그대로 통과시킨다.
4. 지수화 노드이기 때문에, 3에서 받은 인수에 e^(-x)를 곱한다. *-x는 exp노드의 순전파에서의 입력값
5. 곱셈 노드이기 때문에, 4에서 받은 인수에, -1을 곱한다. *-1은 곱셈노드의 순전파에서 입력값에 곱해진 값

위의 과정을 거치면, 아래와 같이 간단하게 표현할 수 있습니다.
즉, 위의 귀찮고 복잡한 순전파 역전파 구현 과정을 한번만 거치면, x의 변화가 초래하는 y의 변화를 짧은시간에 파악할 수 있는것이죠.


5. 렐루(Relu) 활성화 함수
실제로 가장 많이 응용되는 활성화 함수의 하나인, 렐루 함수를 살펴보시죠.

렐루 함수 노드의 순전파 먼저 생각해봅시다.
1. x인수를 받는다.
2. 1에서 받은 인수가 0보다 크면 x를 내보내고, 1에서 받은 인수가 0보다 작거나 같으면 0을 내보낸다.
렐루 함수 노드의 역전파를 생각해보시죠.
1. y에 대한 손실함수(L)의 기울기(dout)를 받는다.
2. 순전파에서 받은 인수가 0보다 크면 x에 대한 x의 미분값인 1을 내보낸다.
순전파에서 받은 인수가 1보다 크면 0에 대한 x의 미분값인 0을 내보낸다.


<연쇄법칙의 일반화>
Z가 t1, t2, t3, ... , tn에 대하여 미분 가능한 함수이고,
tj가 x1, x2, x3 ..., xm에 대하여 미분 가능한 함수이면,
x에 대한 Z의 미분을 다음과 같이 표현할 수 있다.

위 관계식을 풀어서 설명하자면 이러합니다.
Z가 tj들의 함수식이고, tj가 xi들에 대한 함수식으로 표현되면,
xi의 변화에 의한 Z의 총 변화율 = 각 tj에 대한 Z의 변화율 * xi에 대한 tj의 변화율의 합 이다.
즉, xi의 변화에 의해 초래된 tj의 변화에, tj에 의해 z가 변화한 정도를 곱해 모두 더해주면 x1, x2, x3, ..., xm의 변화에 의한 Z의 총 변화율을 구할 수 있는것이죠.
5. 행렬(Matrix)의 내적(dot product)
우선 가장 간단한 행렬(편향을 고려하지 않은)의 계산 그래프를 살펴봅시다.
X는 입력값(input)을 의미하고
W는 각 입력값에 곱해질 매개변수(parameter)를 의미합니다.

행렬의 곱셈이 성립되기 위해서는, 첫째 행렬의 열(column) 개수와 둘째 행렬의 행(row) 개수가 동일해야 한다는것을 잊지 마세요!
(N,M) = (N,D) * (D*M) 이므로, Y = X*W가 성립됩니다.
우리는 위 계산그래프에서 X에 대한 Y의 미분과, W에 대한 Y의 미분에 관심이 있습니다.
계산그래프가 한개 이상의 행과 열로 구성된 행렬을 포함할때는, 똑같이 연쇄법칙을 이용하지만, 계산법이 약간 복잡해집니다.
하나씩 살펴보시죠.
<X에 대한 L의 미분>
우선, X에 대한 최종 output인 손실함수 L의 미분을 구해봅시다.
역시 연쇄법칙을 이용해 다음과 같이 표기할 수 있습니다.
X는 한개이상의 열과 행으로 이루어진 행렬이므로, X 행렬 내부의 각각의 성분의 변화에 따른, L의 변화를 살펴봅시다.
X의 (i, j)번째 성분의 변화에 따른 L의 총 변화량은,
X의 (i, j)번째 성분의 변화에 따른 Y의 (a,b)번째 성분의 변화량과, Y의 (a,b)번째 성분의 변화량에 따른 L의 변화량을 모두 더하여 구해집니다.
즉, X의 (i,j)라는 X 행렬의 하나의 성분이, Y의 행렬의 많은 요소에 변화를 일으키고, 이 Y의 하나하나 성분의 변화에 의해 이루어진 Z의 변화량을 모두 더하면, X(i,j)가 최종 출력값인 L에 미치는 영향을 구할 수 있게 되는것이죠.

Y(a,b)는 다음과 같이 표현되어 우리는 X에 대한 손실함수의 미분을 간소화 시킬 수 있습니다.
Y의 a 행 b열의 요소는 X의 a번째 행의 요소들과 W의 b번째 열의 요소들을 곱한후 더해줌으로써 계산됩니다.
즉, Y의 a 행 b열의 요소는 X의 a번째 행과 W의 b번째 열의 내적으로 계산됩니다.
밑의 예시를 살펴보면 직관적으로 이해가 가능할것입니다.
*행렬의 계산은 딥러닝 구현에 있어서 가장 기본적인 개념인데, 이에 대한 규칙에 있어서는, 조만간 글 올리도록 하겠습니다:)

따라서, 우리가 표기 변환한 Y(a,b)를 X(i,j) 로 미분해봅시다.
Y의 a 행 b열의 요소는 X의 a번째 행과 W의 b번째 열의 내적으로 계산되기 때문에, 다음과 같이 표현 할 수 있습니다. i = a일때, X(i, j)의 변화는 X(a,k)에 영향을 미치기 때문에, 미분값이 W(j,b)로 유효하지만,
i != a 일때는, X(i, j)의 변화는 X(a,k)에 영향을 미치지 않기 때문에, X(i, j)에 대한 X(a,k)의 미분값이 0이 되어, X의 i행, j열 성분의 변화는 Y의 a행, b열의 성분변화에 영향을 미치지 않습니다.
말로 쉽게 풀어 설명하자면, Y의 a번째 행에 영향을 미치는것은 X의 a번째 행입니다. X의 a번째 행이 아닌 다른 행의 요소를 변화시키면, 그 행의변화에 의한 Y의 변화량은 0이 되는것이죠. 위의 예시에서 살펴보자면, Y의 첫번째 행에 영향을 미치는것은 X의 첫번째 행의 요소들인 (x11, x12, x13)이라는것을 알 수 있죠. X의 두번째 행의 변화는 Y의 첫번째 행에 아무런 영향도 끼치지 못합니다.
따라서 X(i,j)에 대한 Y(a,b)의 미분을 다음과 같이 표기하면,
우리는 X의 (i,j)번째 성분의 변화에 따른 L의 변화를 최종적으로 수식화할 수 있습니다.
X의 (i,j)번째 성분의 변화에 따른 L의 변화는, Y의 i 번째 행의 변화에 대한 L의 변화량과 W의 (j,b)번째 성분의 곱으로 구해집니다.
행렬의 곱셈이 성립되기 위해서는, 첫째 행렬의 열(column) 개수와 둘째 행렬의 행(row) 개수가 동일해야 하기 때문에, W의 (j,b)번째 요소는 W의 전치행렬(transpose)의 (b,j)번째 요소로 만들어 Y의 변화에 따른 L의 변화량의 b번째 열을 W의 전치행렬의 의 b번째 행에 곱해주어, Y의 i 번째 행의 변화에 대한 L의 변화량과 W의 (j,b)번째 성분의 곱을 구할 수 있고, 따라서 X의 (i,j)번째성분의 변화에 따른 손실함수(L)의 최종출력값의 변화값을 구할 수 있게 됩니다.

*행렬의 전치(transpose)에 익숙하지 않은 분들을 위해, 이에 대한 간단한 설명을 첨부합니다.

<W에 대한 L의 미분>
X에 대한 L의 미분에 대해서, 차근차근 단계별로 살펴보았으므로, 이 과정과 매우 유사한
W에 대한 L의 미분은 수식으로 간단하게 표현하겠습니다.

<B에 대한 L의 미분>
이제 편향(B)을 고려한 행렬의 내적 계산 그래프를 살펴봅시다. 편향은, 퍼셉트론의 매개변수로, 뉴런이 너무 쉽게 활성화되는것을 제어하는 역할을 합니다.

우리는 앞서, 덧셈노드의 역전파에서는 입력신호(z에 대한 L의 기울기)를 다음노드로 그대로 전달함을 증명하였죠.
하지만, 노드에 행렬이 흐를때에는, 약간의 변환이 필요합니다.
B는 M의 성분으로 구성된 벡터인데, N개의 행과, M개의 열로 표현되는 Y의 행렬에 더할때, 다음과 같이 계산되죠.
B를 3개의 성분으로 구성된 벡터, x_w를 3개의 행과 3개의 열로 표현되는 벡터로 예시를 들어, (3,3)행렬에 (3,)벡터가 더해지면 어떻게 계산되는지 살펴보시죠.
B의 첫번째 요소는 x_w의 첫번째 열에,
B의 두번째 요소는 x_w의 두번째 열에, B의 세번째 요소는 x_w의 세번째 열에, 더해지는것을 볼 수 있으시죠.

앞에서 예시를 통해 대략적으로 살펴보았다 시피, 편향의 벡터에서 n번째 요소는, X*Y의 n번째 열에만 영향을 끼칩니다.
따라서, 편향의 벡터에서 n번째 요소는, Y의 n번째 열에만 영향을 끼친는것을 최종적으로 도출 할 수 있죠.

B의 변화가 최종 출력값인 L에 얼마만큼의 변화를 초래하는지 파악하기 위해서는,
B의 요소의 변화가 Y의 열의 변화들을 파악해, Y의 열의 변화가 L의 변화에 어떠한 영향을 미치는지 파악하는 과정을 거쳐야 겠죠.
즉, B의 첫번째 요소가 Y의 첫번째 열에 변화를 초래하고, Y의 첫번째 열의 변화가 최종 출력값인 L에 어떠한 영향을 미치는지,
B의 두번째 요소가 Y의 두번째 열에 어떠한 변화를 초래하고, 그로 인한 Y의 두번째 열의 변화가 L에 어떠한 영향을 미치는지를 모두 합하면, B가 최종적으로 Y에 미치는 영향을 파악 할 수 있습니다.
긴 과정속에 설명한 행렬의 내적을 파이썬으로 구현하면 이러합니다.

Ref. Deep learning from scratch